This cartoon does not exists
Update - 7 June
I’ve started working on the first episode of my own YouTube show!
I am integrating Google Cloud TTS to replace macOS’s “say” command, with SSML being generated by GPT based > on relevant parts of the plot!
TLDR;
Started with the idea of generating comics with GPT4 and Midjourney, ended up with an animated show!
The results are both surprisingly good and very, very cringe.
Source code, prompts etc coming soon!
Here’s the final result:
Please note, the idea is not to put together an automated content farm, I’d like for this to be a tool I can use to develop consistent stories and animate them for a future YouTube channel.
Initial Idea
Like many others, since the beginning of the year I started working with generative AI quite a bit.
First I adopted ChatGPT as a dev Copilot and then started exploring others tools and how they can be combined from a user perspective, simple things, such as generating Midjourney prompts with GPT.
I became particulary interested in generating different perspective, portraits and facial expression of a consistent character (lots of contents on YouTube about this), and that lead me to the idea of generating a comic with Midjorney…
Having the same bias as many other developers, my focus was immediately shifted towards a Comic Generator instead, which is still fine I guess!
Plot “Context”?
So I made a list of what I would probably need to write a concept for a story:
- What kind of show is it?
- General information about the world
- An idea about the format
We're writing single-page stories for a comicbook.
The story revolves around the wacky, controversial, and satirical misadventures of a group of four friends living in a bizarre small town called Obscuriville, where odd, politically incorrect, and absurd events are everyday occurrences. Drawing inspiration from the irreverent and satirical humor of South Park, the show aims to push the boundaries of what's considered appropriate, tackling sensitive topics through humor and satire.
Each episode always ends with a cliffhanger to improve retention.
I would also need some characters, I kept it very generic:
- Alice: <some description>
- Bob: <some description>
Alice and Bob are married and just bought a house together.
So, with that information, I simply asked for a couple of ideas, it came up with:
Alice and Bob decide to visit the Obscureville Ikea Showroom, but Bob gets lost
Note: what I call “GPT” is actually OpenAI Chat Completion API, opportunely tweaked with
systemmessages.
Developing concepts
I heard about something called the “But-Therefore” rule recently.
The idea is simple: Each event is either directly cause by the previous one (therefore) or is an unexpected twist on it (but)
So I asked GPT to apply it to the concept above:
Alice and Bob are at an Ikea showroom
BUT Bob disappears
THEREFORE Alice looks for him and eventually finds him in the bathroom section
BUT Bob is using the toilet on display
THEREFORE Alice is furious
So… This is definately surprising!
Now, for the next trick, can we convert that into an actual script?
Please provide complete list of everything happening in the plot using this format:
`<comma separated subjects>: <action>|<emotion>|<dialog>`
For example:
Panel: Podcast Studio
Lex, Andy: Talking
Lex: "Thank you for the amazing conversation, now, to conclude, what's the meaning of life?"
Andy: "42, obviously, I always wandered why nobody responds you that!"
Lex: angry
Lex: leaves
Panel: Dive bar
Andy: "I don't know what got him angry, he just left!"
...
Note the Panel: trick, that worked like a charm:
Panel: Ikea Store Exterior
Alice, Bob: Enter an Ikea store
Alice: "Ikea, here we go!"
Panel: Ikea kitchen section
Alice, Bob: Enter kitchen section
Alice: "Oh, I love this kitchen design!"
Bob: Nervous
Panel: Ikea tools section
Alice, Bob: Enter tools section
Bob: "Uhm, I just remembered I need to check some screws in the bathroom section."
Alice: "Oh, I see Mr. Handyman. Have fun!"
Bob: Exits the scene
Panel: Ikea bedroom showroom
Alice: Enters bedroom showroom
Alice: "Where did you go?"
Alice: "I should have brought the leash...I can't believe I lost you, Bob."
Panel: Ikea bathroom showroom
Alice: Enters bathroom showroom
Bob: Using the toilet on the display
Bob: Embarrassed
Alice: "Bob?! What in the actual hell?!"
Alice: Angry
Alice: "Real bathrooms have 4 walls, Bob... FOUR!!"
Why comic when you can video?
I have already mentioned South Park in the prompts here as a source of inspiration…
That got me thinking of a faster way to render different facial expressions in my comic, and I ended up implementing a simple South Park-like talking sequence.
I was immediately sold on it (for some reason), replaced “Panel” with “Scene” in the prompts above and that’s it!
Representing a scene
Everything so far is a series of Python scripts, this bit instead is done in Swift, as I wanted to package this in an macOS app (for personal use) later on.
I went with the simplest implementation I could think of:
- A scene is represented as a tree
- Each node can an offset from its parent, rotation info etc
- Each node can have an image
- There’s an update method that takes a time param
Not exactly elegant, but does the job:
protocol SceneNode {
var angleZ: CGFloat { get set }
var position: CGPoint { get set }
var size: CGSize { get set }
var imagePath: String? { get set }
var nodes: [SceneNode] { get }
func update(time: TimeInterval)
func position(at: ScenePosition)
func turn(to: Direction)
}
Not exactly clean, but it will allow me to call the update method, depth-first, and build an image for each frame.
Adding Animations
Now the question is how do I animate things in a way that GPT can easily approach, and as I think about it… Am I optimizing this for machine use rather than human use?
I came up with this syntax, as it follows the natural language:
// Panel: Ikea Store Exterior
let scene = Scene(background: "ikea_store_exterior")
// Alice, Bob
let alice = scene.add(Alice())
let bob = scene.add(Bob())
// Alice, Bob: Enter an Ikea store
alice.say(line: "Ikea here we go!")
alice.walk(to: .farLeft)
bob.walk(to: .farLeft)
This is obviosly not great, as it does not give me control over the order and timing of operations, so I added a simple queue to the mix:
protocol ExecutionPipeline {
func post(action: @escaping Action)
func post(speaker: SceneNode, line: String)
func post(pause: TimeInterval)
func post(speaker: SceneNode, line: Int)
func update(currentTime: TimeInterval)
}
The idea here is that I can “post” some actions and execute them in order, one by one, as I call the update method, to better understand the effect:
// Alice says "hello" and "how are you?" at the same time.
// The voice will obviously overlap, which is bad...
// Alice walks while talking.
alice.say(line: "Hello")
alice.say(line: "how are you?")
alice.walk(to: .farLeft)
// Bob says "hello"
// Then bob says "how are you?"
// Then bob starts walking
pipeline.post(speaker: bob, line: "Hello")
pipeline.post(speaker: bob, line: "how are you?")
pipeline.post {
bob.walk(to: .farLeft)
}
Run pipeline.update(time:) a couple of times, compile images into an MP4, add TTS on top of it, and what you get is basically Cartoon as Code!
It’s turning from not very clean to ugly, but let’s remember it’s optimized for GPT, and it’s easy to explain how to use the pipeline in a prompt:
Actions from script are posted to an execution pipeline:
<protocol ExecutablePipeline>
Actions happening in parallel should be posted with the same closure, closures are executed one at a time, in order:
<Alice and Bob example for earlier>
For simplicity, let’s call this solution I hacked together “the framework”…
Can GPT use the framework?
We obviously know GPT4 can code, so we just need to add the relevant bits of our framework to its context window.
I found a creative solution for sharing code with GPT automatically…
In my codebase I have some special delimiter comments:
// ## Prompt: ScenePosition
enum ScenePosition {
case outsideLeft
...
}
// ##
Which I then use to retrive the code I need to embed in the prompt, for example:
prompt_scene_position = swift_code_for_tag('ScenePosition')
codegen_prompt.append(
'''
The frameworks allows characters to be placed anywhere on the screen via CGPoint, or at fixed positions:
{prompt_scene_position}
'''
)
This allows me to share snippets of the code which can be updated without much worry of also editing the prompts.
I also found that sharing a protocol yields better results than sharing a class.
I thought about this a bit and my conclusion is that GPT sees protocols a good summary for classes:
- Simpler interface
- Less code (remember: Context window has a finite size!)
- No unnecessary implementation details
So I created protocols for each relevant structure and class of the framework.
There’s better solutions, but this one worked decently so far!
Cartoon as code
There’s obviously quite a bit of details I left out, but this is what we get in the end:
class AliceAndBobIkeaScene {
static func scene() -> ExecutableScene {
let pipeline = ExecutionPipelineImpl()
let scene = Root(path: "background_ikea_exterior")
let alice = scene.add(Alice())
alice.position(at: .centerRight)
let bob = scene.add(Bob())
bob.position(at: .center)
pipeline.post {
alice.walk(to: .farLeft)
bob.walk(to: .farLeft)
}
pipeline.post(speaker: alice, line: "Ikea, here we go!")
pipeline.post(pause: 1)
pipeline.post {
alice.position(at: .centerLeft)
bob.position(at: .farLeft)
scene.path = "background_ikea_kitchen"
alice.walk(to: .outsideRight)
bob.walk(to: .outsideRight)
bob.setEmotion(.worried)
}
pipeline.post(speaker: alice, line: "Oh, I love this kitchen design!")
pipeline.post(speaker: bob, line: "Ehm... Sure...")
pipeline.post {
bob.stopWalking()
}
pipeline.post(pause: 1)
pipeline.post {
bob.walk(to: .outsideLeft)
}
pipeline.post(pause: 1)
pipeline.post {
alice.position(at: .centerLeft)
bob.position(at: .outsideLeft)
scene.path = "background_ikea_bedrooms"
alice.walk(to: .outsideRight)
}
pipeline.post(speaker: alice, line: "Where did you go?")
pipeline.post(speaker: alice, line: "I should have brought the leash...I can't believe I lost you, Bob.")
pipeline.post {
alice.position(at: .farLeft)
scene.path = "background_ikea_bathrooms_bob"
alice.walk(to: .center)
}
pipeline.post {
alice.setEmotion(.worried)
}
pipeline.post(speaker: alice, line: "Bob?! What in the actual hell?!")
pipeline.post {
alice.setEmotion(.angry)
bob.setEmotion(.worried)
}
pipeline.post(speaker: alice, line: "Real bathrooms have 4 walls, Bob... FOUR!!")
return ExecutableScene(scene: scene, pipeline: pipeline)
}
}
Speech Synthesis and Lip-sync
I switched to Google Cloud Text to Speech with Neural voices, which by itself is already miles better than what macOS say command could offer.
But the real deal is SSML (Speech Synthesis Markup Language) generation, as with that, you can make sure:
- Words are spelled correctly
- There’s emphasis on the correct words
- Speech “effects” can be applied (ie. “Ooook” will have a long “o”, rather than a “u”)
- We can attach informations about emotion, which seems to not be supported by Google TTS at the time of writing, but it doesn’t hurt to try!
For example:
<speak>
<prosody rate="medium">
<emphasis level="strong">
<voice emotion="desperation">
Real bathrooms have 4 walls Bob...
</voice>
</emphasis>
<break time="150ms"/>
<voice emotion="anger">
<emphasis level="strong">
FOUR!!
</emphasis>
</voice>
</prosody>
</speak>
Audio without SSML:
Audio with SSML:
The difference is subtle, but it’s there.
Prompt here is also very simple, and Gpt 3.5 was more than capable of performing the task:
You are an AI that converts a given line of dialog to SSML based on some context (if available).
For example:
Context:
- Alice: Bothered
- Alice: "I should have brought the leash..."
- Alice: Enters bathroom showroom
- Bob: Using the toilet on display
- Bob: Embarassed
- Alice: Angry
- Alice: "Real bathrooms have 4 walls Bob... FOUR!!"
Dialog:
"Real bathrooms have 4 walls Bob... FOUR!!"
Your output:
<some example>
Context might not be always provided, you will need to take a guess based on the sentence, or simply avoid emphasis if it cannot be inferred.
You will not refuse to produce an output.
You will not ask for further information.
Your response will always and only be a valid SSML based on the text provided.
You will not include links to external audio resources in your response.
Don't include external audio resources, don't use the <audio src= tag.
The SSML should only include the voice of the speaker in the given line of dialog.
You will might use the <voice> tag to communicate emotion or other things, but never a voice name.
Finally, some words will be mispelled on purpose, such as "oook" instead of "ok" or "soooo" instead of "so", make sure those are spelled with a long "o", rather than a "u", for example:
`Oook, sooo I think I'm gonna go now`
Should produce the following:
<some example>
Special Effects
Initially, I was using sprites for special effects like fire and explosions, as that fits very well with the scene-as-a-tree model, but I’ve then moved to a simpler approach.
Posting an effect to the pipeline simply allows a green-screen video to be enqueued at a certain time, which will then be overlayed on top of the rest of the scene at build-time.
The video is simply centered on top of the subject of the effect.
Getting a video out of it
As mentioned the process is quite straightforward:
- Used Google Cloud TTS to generate voices from a SSML generated by GPT, based on the script
- Based on audio volume while a character talks, I am able to implement basic lip-sync (for pauses mid-sentence, or shouting)
- For each frame, update the scene -
pipeline.update() - For each frame, create an image -
sceneRendering.render(scene:) - Used AVFoundation to merge the images into a video
- Used AVFoundation to merge audio and video
- Used AVFoundation to overlap green-screen clips onto the video for basic effects (like explosions)
- Write this article
- Upload the final result on YouTube!
If there is enough people interested i might share the code or talk about the use of AVFoundation in generating the video, we’ll see!
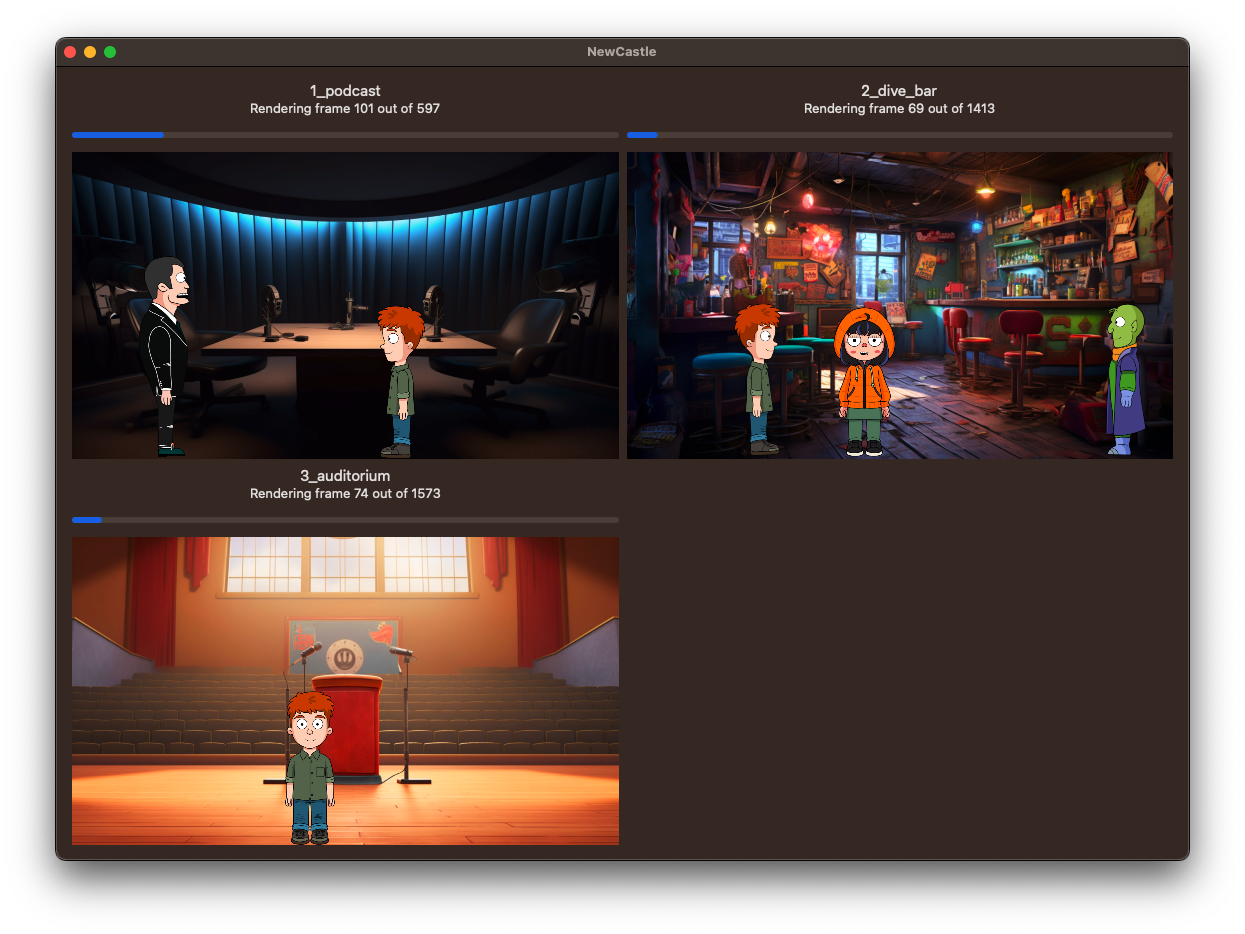
Screenshots
PS. If you got this far, thanks for reading my article!